Code
cdc.idaho.proj <- st_transform(cdc.idaho, crs=st_crs(hospital.int.overlaps))
plot(st_geometry(cdc.idaho.proj), col="purple")
plot(st_geometry(hospital.int.overlaps), add=TRUE)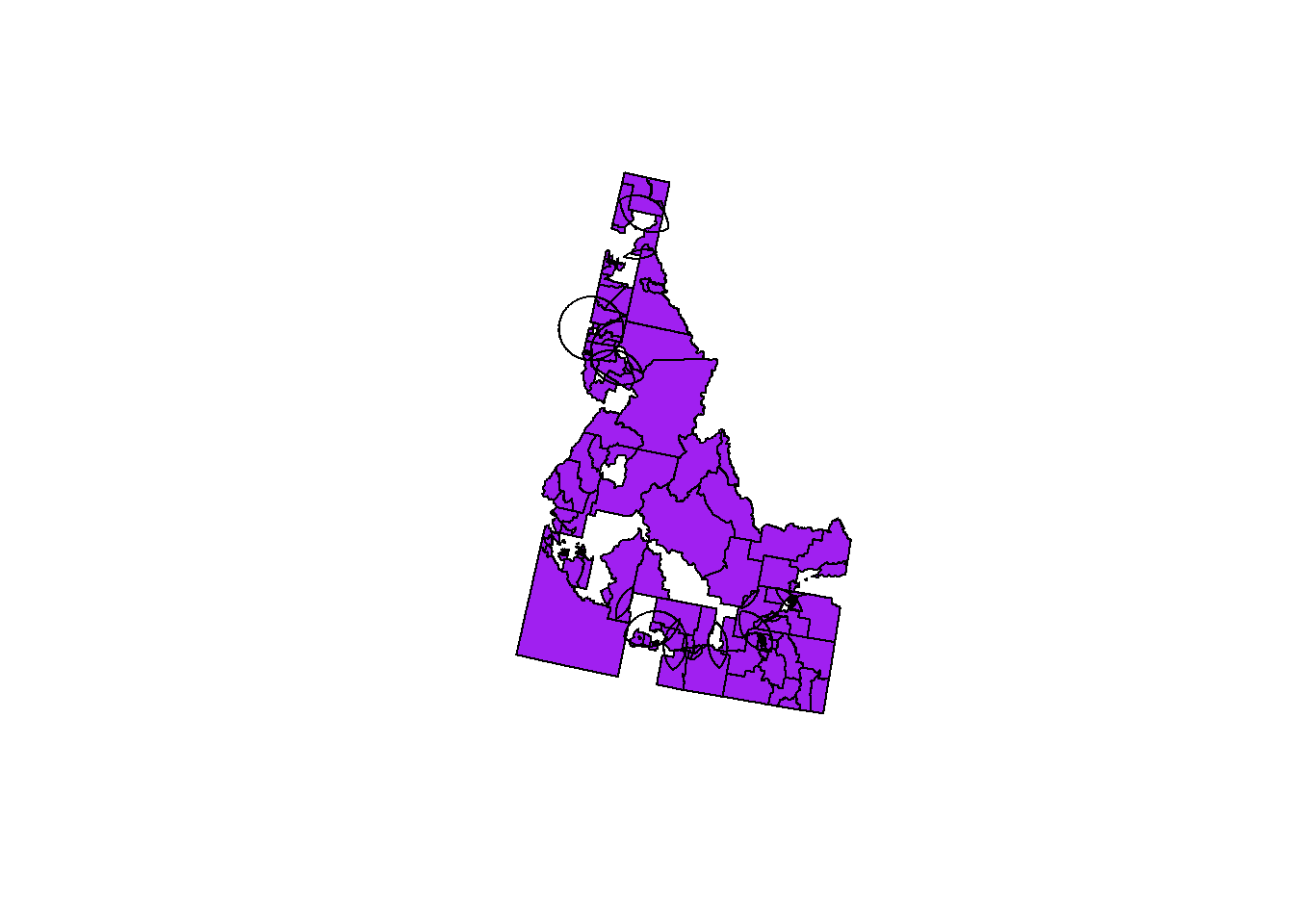
Code for questions 1 and 2 can be found in Session 11, in both the slides and the Panopto recording.

We did this in the previous questions – the dataset is cdc.idaho.
We did this in the previous questions – the dataset is hospital.sf.proj.
We did this in the previous questions – the dataset is hospital.buf.
We did this in the previous questions – the dataset is hospital.int.overlaps. However, we re-projected it, so now we need to project cdc.idaho to the same projection. A plot shows that they are aligned.
cdc.idaho.proj <- st_transform(cdc.idaho, crs=st_crs(hospital.int.overlaps))
plot(st_geometry(cdc.idaho.proj), col="purple")
plot(st_geometry(hospital.int.overlaps), add=TRUE)
overlap.tracts.matrix <- st_intersects(cdc.idaho.proj, hospital.int.overlaps, sparse = FALSE)
overlap.tracts.matrix[1:12, 1:5] [,1] [,2] [,3] [,4] [,5]
[1,] FALSE FALSE FALSE FALSE FALSE
[2,] FALSE FALSE FALSE FALSE FALSE
[3,] FALSE FALSE FALSE FALSE FALSE
[4,] FALSE FALSE FALSE FALSE FALSE
[5,] FALSE FALSE TRUE FALSE FALSE
[6,] FALSE FALSE TRUE FALSE FALSE
[7,] FALSE FALSE TRUE FALSE FALSE
[8,] FALSE FALSE TRUE FALSE FALSE
[9,] FALSE FALSE TRUE FALSE FALSE
[10,] FALSE FALSE TRUE FALSE FALSE
[11,] FALSE FALSE TRUE FALSE FALSE
[12,] FALSE FALSE TRUE FALSE FALSEThis creates a logical matrix where each row corresponds to a tract, and the cells in the matrix show whether it overlaps with each overlap area (TRUE) or whether it does not (FALSE). The cool thing about logicals is that they also count as numbers (TRUE = 1, FALSE = 0). By finding the rowSums, we can see which tracts overlap with 2+ hospital areas (rowSum >= 1) and which don’t (rowSum = 0).
overlap.tracts.filter <- rowSums(overlap.tracts.matrix)
overlap.tracts <- cdc.idaho.proj[overlap.tracts.filter>=1, ]
plot(st_geometry(overlap.tracts), col="cornflowerblue")
plot(st_geometry(hospital.int.overlaps), add=TRUE, col="orange")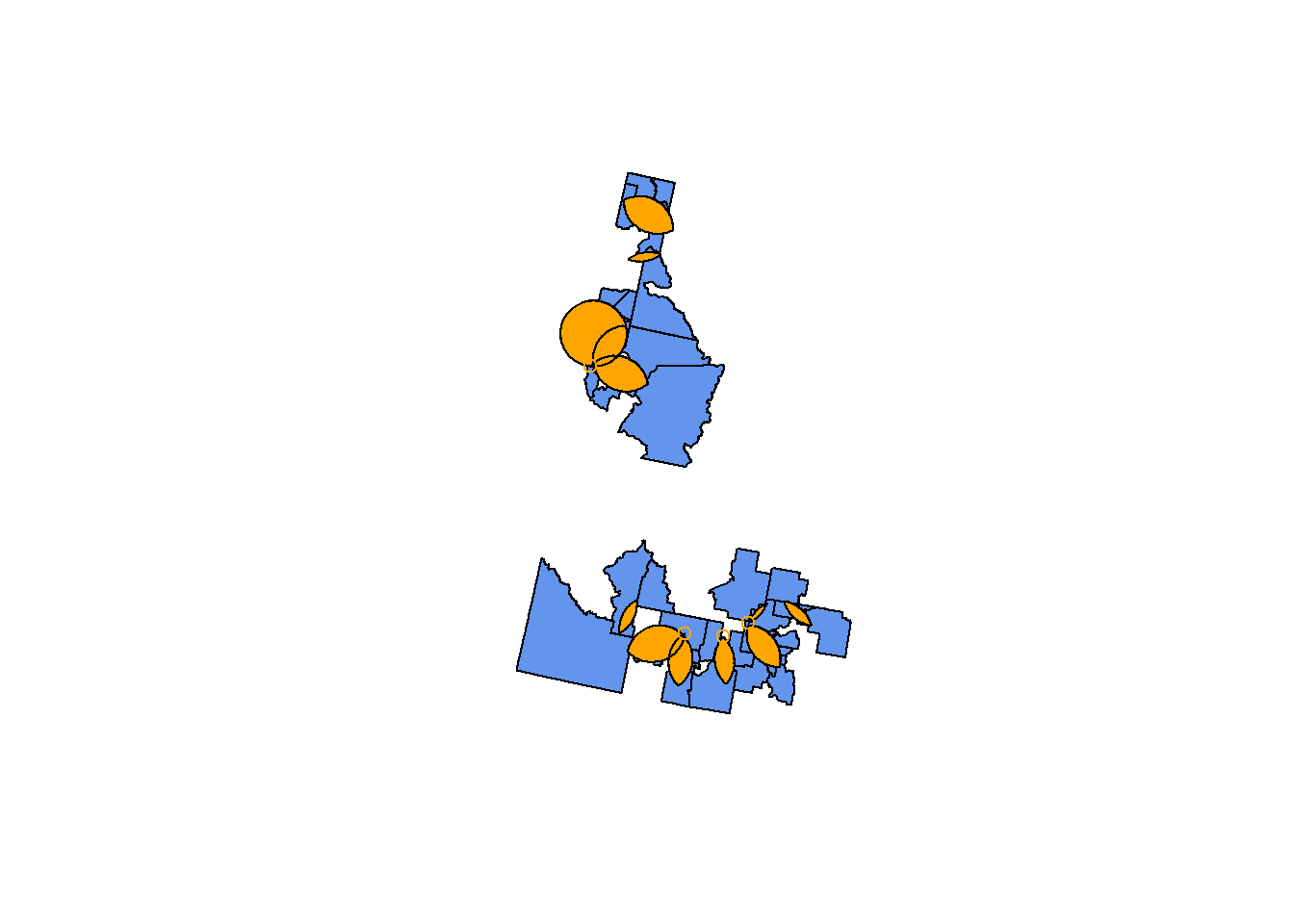
For an alternate tidyverse integration, see this Stack Overflow question.
We’ll use the same process as step 5, but this time we’ll keep the rowSums that are equal to 0.
nohosp.tracts.matrix <- st_intersects(cdc.idaho.proj, hospital.buf, sparse = FALSE)
nohosp.tracts.matrix[1:12, 1:5] [,1] [,2] [,3] [,4] [,5]
[1,] FALSE FALSE FALSE FALSE FALSE
[2,] FALSE FALSE FALSE FALSE FALSE
[3,] FALSE FALSE FALSE FALSE FALSE
[4,] FALSE FALSE FALSE FALSE FALSE
[5,] FALSE FALSE TRUE FALSE FALSE
[6,] FALSE FALSE TRUE FALSE FALSE
[7,] FALSE FALSE TRUE FALSE FALSE
[8,] FALSE FALSE TRUE FALSE FALSE
[9,] FALSE FALSE TRUE FALSE FALSE
[10,] FALSE FALSE TRUE FALSE FALSE
[11,] FALSE FALSE TRUE FALSE FALSE
[12,] FALSE FALSE TRUE FALSE FALSEnohosp.tracts.filter <- rowSums(nohosp.tracts.matrix)
nohosp.tracts <- cdc.idaho.proj[nohosp.tracts.filter==0, ]
plot(st_geometry(nohosp.tracts), col="firebrick")
plot(st_geometry(hospital.buf), add=TRUE, col="orange")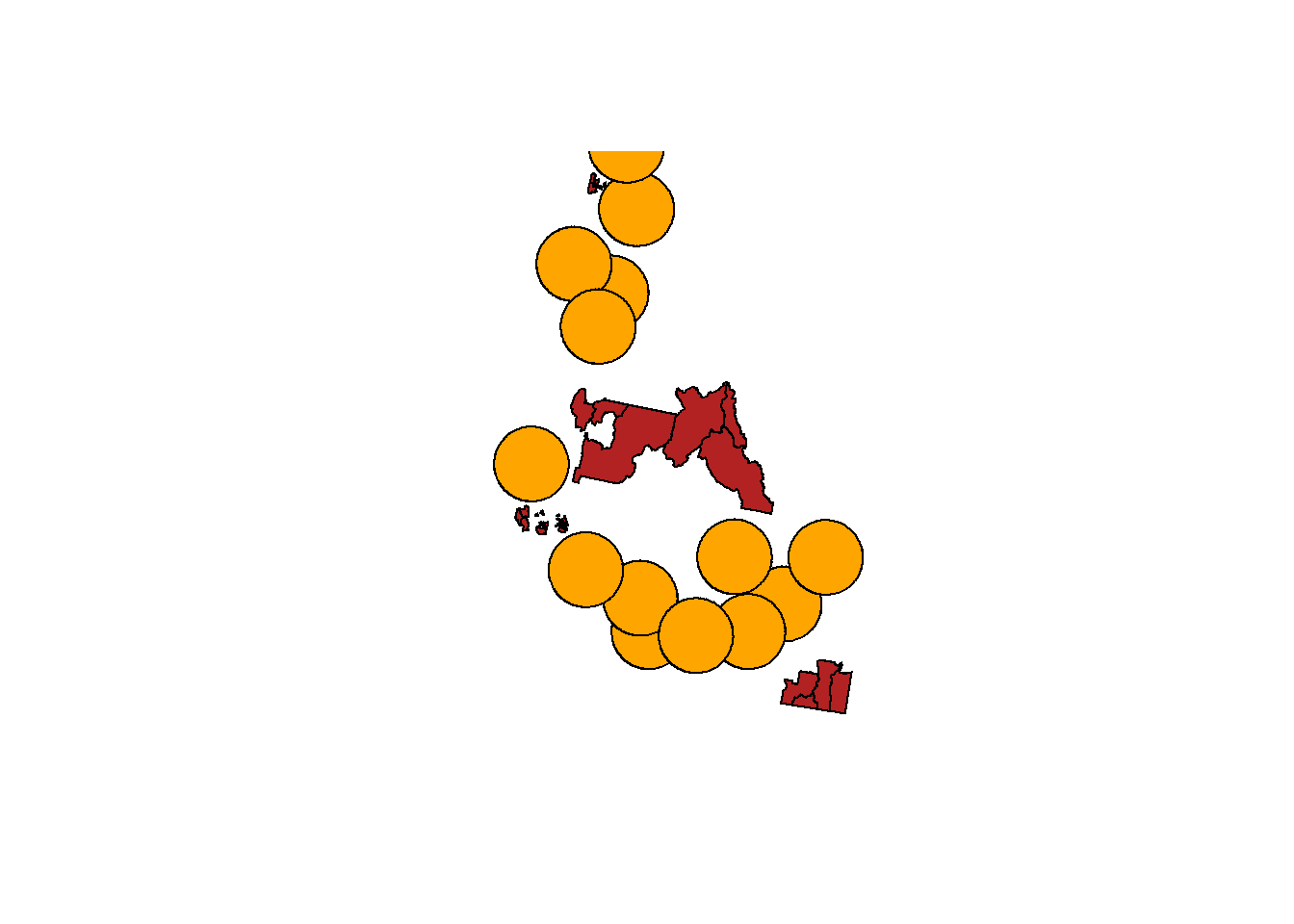
avg.nohosp.rate <- mean(nohosp.tracts$chd_crudep)
avg.overlaps.rate <- mean(overlap.tracts$chd_crudep)avg.overlaps.rate - avg.nohosp.rate[1] 0.36875The rates of chronic heart disease are on average higher in tracts with multiple hospitals than those with no hospitals. Maybe there’s less access to a diagnosis, or heart disease is more fatal to people with less hospital access…?